
KTX의 빈자리 알림을 보내주는 서비스를 개발하고 있습니다.
개요
저희 서비스에서는 KTX의 열차 시간표를 공공 API를 통해 가져옵니다.
공공 API의 제약 조건은 다음과 같습니다.
1. 요청 날짜로부터 일주일 후 열차 시간표 까지 가져올 수 있습니다.
2. 출발 기차역, 도착 기차역, 출발 날짜가 모두 같은 경우 한꺼번에 데이터를 가져올수 있습니다.
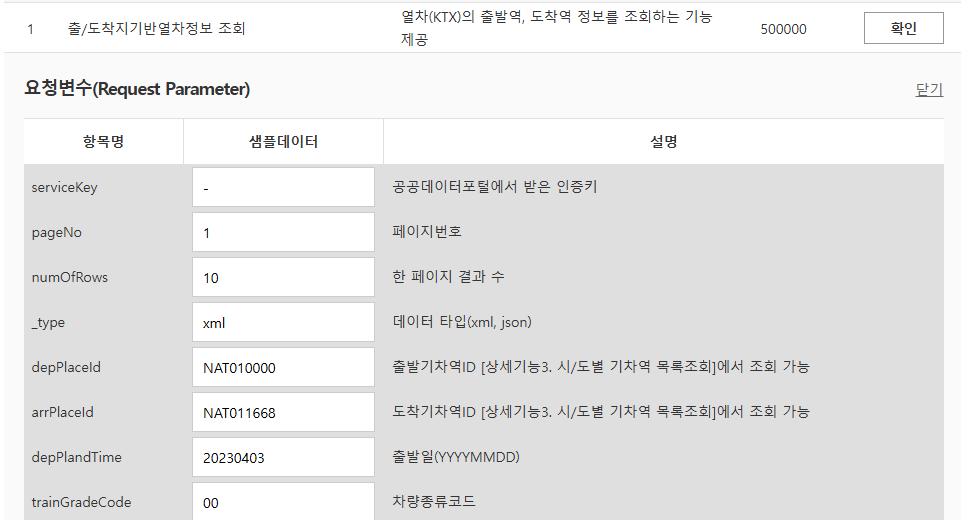
그래서 저희는 매일 새벽마다 그 다음 날 열차 정보를 가져와서 DB에 삽입 해야했고, 이 작업은 배치 서버에서 수행되었습니다.
첫번째 시도 : 최대한 많은 데이터를 한번에 공공 API를 통해 가져옴
먼저 공공 API와 통신에 드는 시간인 IO 비용을 최대한으로 줄이기 위해, 출발 기차역, 도착 기차역, 출발 날짜가 모두 같은 경우 데이터를 한번에 다 가져오도록 API의 파라미터인 numOfRow를 최대로 하고 이를 List에 넣고 saveAll을 통해 DB에 Insert 했습니다.
save가 아닌 saveAll을 사용한 이유는 불필요한 트랜젝션 Proxy 로직이 추가되는 것을 줄이기 위해서 입니다.
자세한 내용은 https://www.baeldung.com/spring-data-save-saveall , https://sjparkk-dev1og.tistory.com/232 참고
하지만 워낙 출발기차역, 도착 기차역이 많았기 때문에 굉장히 많은 시간이 걸렸습니다.
두번째 시도 : 병렬 프로그래밍을 통해 한번에 여러번 공공 API에 요청을 보냄
병렬 프로그래밍을 사용하여 여러 스레드가 동시에 공공 API에 요청을 보내고, 응답으로 받은 데이터를 List로 말아서 한번에 saveAll() 메서드로 저장했습니다.
(문제점)

Spring data jpa 의 saveAll() 메서드는 일일이 데이터를 save() 하는거 보단 빠르지만 결국 각 데이터마다 insert 쿼리가 발생하여 속도가 느려집니다.
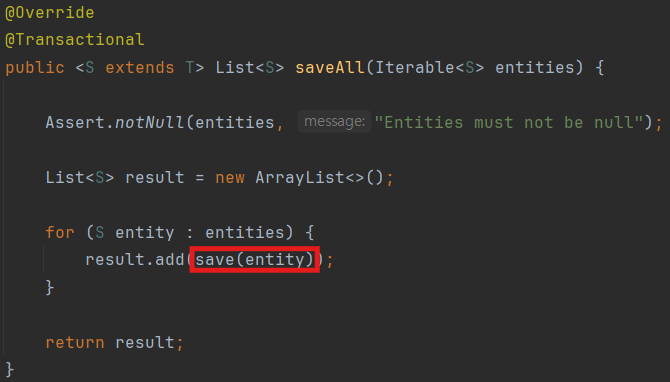
내부 코드를 보면 saveAll도 결국 save를 여러번 호출함을 확인 할수 있습니다.
* 왜 단건 insert 쿼리가 벌크 Insert 쿼리보다 느릴까?
1. I/O 작업 비용이 늘어납니다.
2. DBCP 커넥션 풀 자원을 잡아 먹는다.
세번째 시도 : JDBC를 이용하여 Bulk Insert
제가 원했던 동작은 벌크 쿼리 였기 때문에 JDBC를 사용하여 Bulk 쿼리를 날리기로 하였습니다.
@Transactional
public void saveAll(List<Ticket> tickets) {
String sql = "INSERT INTO ticket (TICKET_TYPE, DEPART_DATE, DEPART_TIME, DEPART_STATION, ARRIVE_TIME, ARRIVE_STATION, PRICE) VALUES (?, ?, ?, ?, ?, ?, ?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Ticket ticket = tickets.get(i);
ps.setString(1, ticket.getTicketType());
ps.setString(2, ticket.getDepartDate());
ps.setString(3, ticket.getDepartTime());
ps.setString(4, ticket.getDepartStation().name());
ps.setString(5, ticket.getArriveTime());
ps.setString(6, ticket.getArriveStation().name());
ps.setString(7, ticket.getPrice());
}
@Override
public int getBatchSize() {
return tickets.size();
}
});
}
다음과 같이 JdbcTemplate의 batchUpdate를 이용하여 벌크 쿼리를 날렸고 이전 보다는 훨씬 빨라졌지만, 공공 api에서 가져오는 데이터가 많지 않았기 때문에 여전히 여러번 쿼리를 날려야 했습니다.
INFO 14780 --- [pool-3-thread-4] MySQL: [QUERY] INSERT INTO ticket (TICKET_TYPE, DEPART_DATE, DEPART_TIME, DEPART_STATION, ARRIVE_TIME, ARRIVE_STATION, PRICE) VALUES ('KTX-이음 731', '20241127', '20241127090900', '가남', '20241127091500', '감곡장호원', '8400원'),('KTX-이음 733', '20241127', '20241127130500', '가남', '20241127131100', '감곡장호원', '8400원'),('KTX-이음 735', '20241127', '20241127164300', '가남', '20241127164900', '감곡장호원', '8400원'),('KTX-이음 737', '20241127', '20241127202500', '가남', '20241127203100', '감곡장호원', '8400원') [Created on: Sun Nov 24 14:44:53 KST 2024, duration: 35, connection-id: 1289, statement-id: 0, resultset-id: 0, at com.zaxxer.hikari.pool.ProxyStatement.executeBatch(ProxyStatement.java:127)]로깅 결과 벌크 쿼리가 발사됨을 확인 할수 있습니다.
(추가하면 좋을 문제 해결 기법)
JPA Entity에서 ID 생성 전략 변경
JDBC batchUpdate 사용
스프링 배치 사용(taskExecutor)
파티셔닝 -> 일별로 나누면 편함
트렌젝션 크기를 너무 크게 잡으면 느려짐
데이터를 지우는 로직 (데이터를 먼저 지우고 truncate, ttl 걸어놓기)
'기술적 고민 > 자리나따' 카테고리의 다른 글
| [자리나따] flyway 적용기 (Spring boot, JPA, MySQL) (1) | 2024.11.22 |
|---|---|
| [자리나따] 열차 여석 알림 기능을 개발하며 한 고민 (feat. 커넥션 풀, 비동기) (2) | 2024.10.06 |
| [자리나따] 웹 크롤러를 개발 하며 하는 고민 (2) - 데이터 흐름 (0) | 2024.07.22 |